DCAT-BE
Linking data portals across Belgium.
DCAT Belgium is an Application Profile of the W3C standard to describe open datasets
Join the conversation on our mailinglist:
Upcoming meeting
Previous meetings
What is DCAT?
“DCAT is an RDF vocabulary designed to facilitate interoperability between data catalogs published on the Web”
DCAT is a way to provide context or metadata for your datasets. By using DCAT, others can easily find and search across all the datasets published in Belgium in a unified way.
DCAT-BE
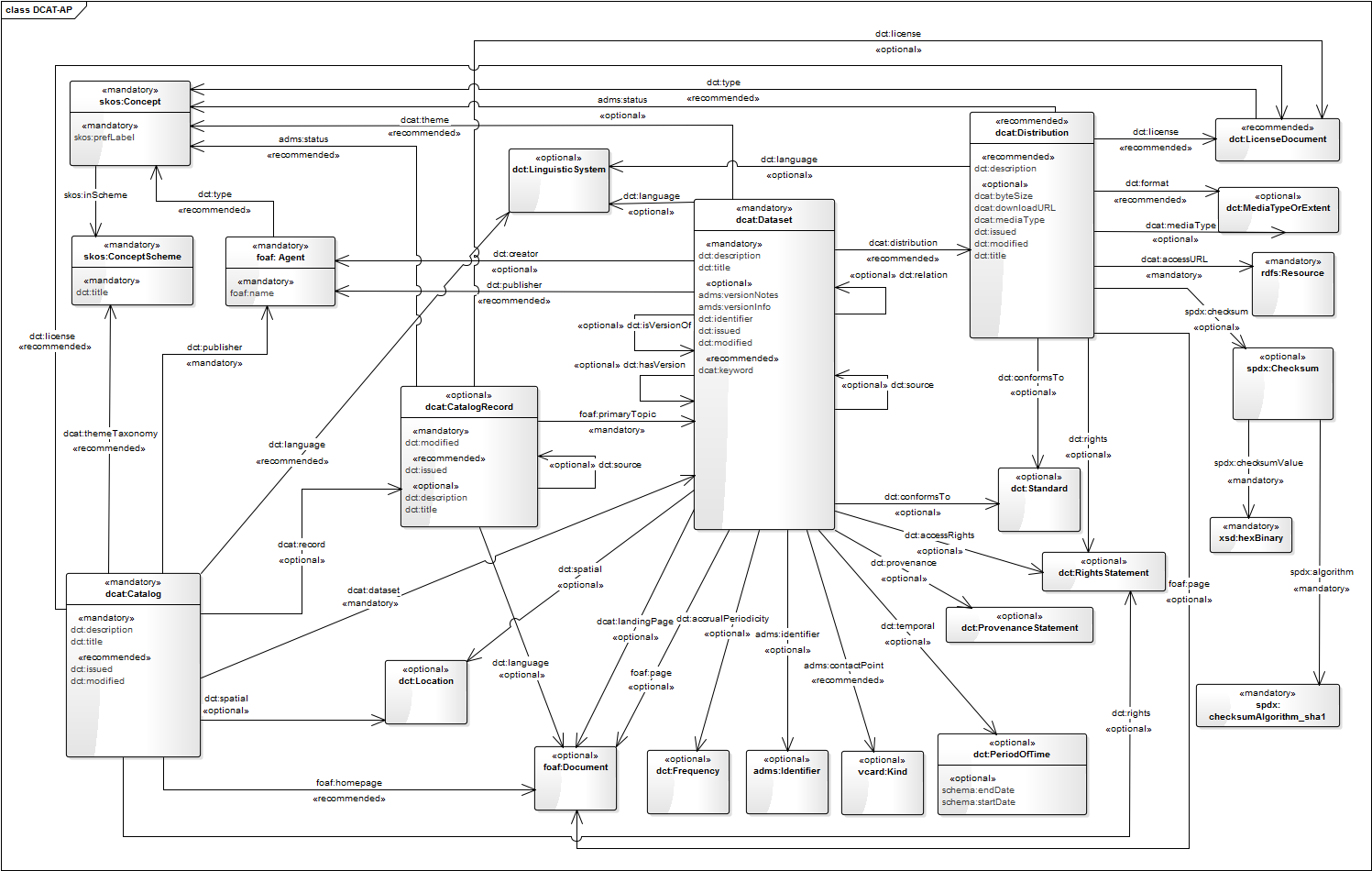
The DCAT-BE standard is derived from the DCAT-AP standard, which in turn is derived from the W3C DCAT standard. DCAT-AP, the European standard, makes some fields mandatory, recommended and optional compared to DCAT. Here is an UML Diagram of all the classes and properties included in the DCAT Application Profile (DCAT-AP).
Currently, DCAT-BE extends DCAT-AP by adding a theme taxonomy for Belgium. The themes are still under discussion.
Tools and resources
{kind=link}

The DataTank is an open-source data adapter: it transforms machine readable datasets into an HTTP API. It automatically generates a DCAT-AP feed for the datasets included.

The Flemish government has made a guide in which they explain how to work with Open Data, as well as give some examples of DCAT, check it out here.

Another option is to define your DCAT within the HTML of your webpage. The Open Data Institue has an excellent guide to get you started.

The DCAT validator shows errors or warnings when certain properties are missing. It's a useful tool to debug your DCAT feed.

The DCAT Drupal module is a module that helps people extract metadata from their websites, which will result in a clean DCAT feed.
DCAT-BE Feeds
There are already a couple of government instances using DCAT in Belgium. Our goal: make all governments who publish open data use DCAT-BE to annotate their repository.
Click on the following links to load a section of the dataset to see a preview of their data. Follow the links to reuse this data.
The basics
DCAT describes datasets on 3 different levels. The Catalog, the Dataset and the Distribution level. Each level contains information, meta-data, about itself, such as the title, description, and so on. Furthermore, the upper layers contains URI references to its children, which means it’s easy to cross-reference all of the data.
dcat:Catalog
The Catalog is the upper level in the DCAT standard. It contains a description of itself, such as the title, description, publisher and licenses. It also contains references to the different Datasets which can be found within this particular Data Catalog.
dcat:Dataset
The Dataset contains information about the individual Dataset, such as the author, which category the dataset belongs to, geographical information, and so on. It also has references to all the different Distribution methods of this particular dataset.
dcat:Distribution
This is the deepest level of the DCAT standard. At this level we define the access URL for the data, type (CSV, JSON, …), license, size, download URL, and so on.
More into detail
Prefixes / Aliases
In this section we define the prefixes, or aliases, which we will use throughout the DCAT file. These are just shorthands for various DCAT fields to make our life easier.
@prefix dcat: <http://www.w3.org/ns/dcat#> . @prefix dc: <http://purl.org/dc/terms/> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
The Data Catalog
In the next section we define our Data Catalog. Here we give our catalog a title, description, language, license, and so on. These fields are all defined on the various websites we declared earlier in our prefix section. We also reference all of the Datasets that are included in this catalog.
<http://demo.thedatatank.com/api/dcat> a dcat:Catalog ; dc:title "The DataTank Demo" ; dc:description "A demo catalog of datasets published by The DataTank." ; dc:issued "2013-12-04T09:35:15+0000" ; dc:language <http://lexvo.org/id/iso639-3/eng> ; foaf:homepage <http://demo.thedatatank.com> ; dc:license <http://www.opendefinition.org/licenses/cc-zero> ; dc:publisher <http://thedatatank.com/#organization> ; dc:modified "2015-05-04T16:04:28+0000" ; dcat:dataset <http://demo.thedatatank.com/csv/geo>, <http://demo.thedatatank.com/json/crime> .
The Dataset
Similar to the Data Catalog, we define the title, description, language, and so on of a single Dataset. Again we make use of the prefixes which we defined earlier. The big difference here is that we link to the "dcat:distribution"-layer. This is the layer where our actual data is linked to, so it's very important for DCAT.
<http://demo.thedatatank.com/csv/geo> a dcat:Dataset ; dc:title "Provinces and districts in Afghanistan" ; dc:description "Geographical data about Afghanistan concerning provinces and districts." ; dc:identifier "csv/geo" ; dc:issued "2013-12-04T09:35:22+0000" ; dc:modified "2015-01-27T16:02:41+0000" ; dc:language <http://lexvo.org/id/iso639-3/ara> ; dc:theme <http://ns.thedatatank.com/dcat/themes#Government> ; dcat:distribution <http://demo.thedatatank.com/csv/geo.json> .
The Distribution
In this relative small layer, we make a link to the actual dataset which we might want to find certain data in. We define the type of data (JSON, XML, ...), the license and most important, where we can find the dataset.
<http://demo.thedatatank.com/csv/geo.json> a dcat:Distribution ; dc:description "A json feed of http://demo.thedatatank.com/csv/geo" ; dc:mediaType "application/json" ; dc:license <http://www.opendefinition.org/licenses/gfdl> .
Partners








